

人是视觉动物,要用数据把一个故事讲活,图表是必不可少的。如果你经常看到做数据分析同事,在SQL客户端里执行完查询,把结果复制/粘贴到Excel里再做成图表,那说明你的公司缺少一个可靠的数据可视化平台。数据可视化是Business Intelligence(简称BI)中的核心功能,有许多成熟的商用解决方案,如老牌的Tableau, Qilk,新生代的Looker,国内的FineBI等等。不过对于许多小公司来说,这些服务的License费用是一笔不小的开销,且有一种“杀鸡用牛刀”的感觉。那在开源软件如此发达的今天,在数据可视化方面,有什么靠谱的方案可以选择呢?今天给大家介绍三个比较知名的项目,分别是Superset, Redash和Metabase。前两个我都在产生环境中实际使用过,在本文中会重点介绍。Metabase我只是试玩了一下,但我觉得这是一个非常有想法的项目,所以也会和大家聊聊我对它的看法。
选择一个称手的工具,功能上能满足我的需求肯定是首要的。就先从功能需求讲起,我们的数据仓库用的是Amazon Redshift(如果你没听过Redshift,就把它看作是为大数据优化过的PostgreSQL),所以大部分的实际用例都是要将一个SQL查询的结果可视化。我们所需的图表类型也就是常用的那几种,包括折线图,柱形图,饼图等。有了图表之后,接下去就是把相关的图表排版,生成报表页面(Dashboard)。从数据安全性角度,我不希望每个员工都能自由访问所有的Dashboard,所以每个Dashboard需要设置不同的访问级别。另外,我会看重它是否有REST API,能否通过API来创建与管理报表,这部分我们放在以后的文章中再讲。
除了满足功能性需求,易用性与文档在评判一个工具时也是非常重要的。谁不想要一个简单好用,文档清晰的产品呢?
下面我们就从功能性、易用性与文档等方面,来看看这三个开源项目的实际表现吧
Superset

Superset最初是由Airbnb的数据团队开源的,目前已进入Apache Incubator,算是明星级的开源项目。老实讲,我也是被Airbnb与Apache两块金字招牌吸引才入了坑。目前公司绝大部分报表都在Superset上,大大小小有50个Dashboard,包含了近900个图表。在使用Superset之前我们用的是Looker(很不错的商用BI工具,可惜太贵),一年半前把Looker上所有的Dashboard迁移到Superset上,整个过程也很顺利。用了一年多,虽然在不少小地方有些不满意,但总体来说Superset很好地满足了公司现阶段在数据可视化与业务报表方面的需求。
当你把一个数据库连接到Superset上以后,你定义你要用的每一张表。Superset里表的定义不但包括字段,还需要定义指标(Metric)。指标是对字段的某种统计结果,比如字段上值的求和、平均值、最大值、最小值等。是不是有点糊涂了?但请回想一下,BI工具通常是用来做商业分析的。假想一个电商数据库,虽然在数据表我们存储每笔订单的交易额,但在商业分析时上我们不关心单笔交易,我们关心的可能是一个时间段内的总交额,或是平均交易额。当你画交易月报表时,你不会把每笔交易画在图上,而是把每天的总交易额用一个柱形在图上表示。这就是为什么Superset要引入“指标”这个概念。
对于数据分析人员来说,由于在Superset上他们不是直接写SQL,而是通过选择指标(Metric), 分组条件(Group)和过滤条件(Filter)来画图表,所以在构建复杂查询时可能会有些不适应。另一个难题是Superset里的表不支持join,如果一个图表里的数据要从多个数据表里取,那只能通过建视图来实现。Superset在0.11版本之后加入SQL Lab功能,支持从SQL查询结果直接生成图表。可惜,由于这个功能与Superset的核心设计格格不入,所以实现得比较差,没什么实用价值。
客观地讲,Superset里引入自己的表与指标的概念,在逻辑上是合理的,在统一各种异型的数据源时也是必要的。但实际操作中仍会让人觉得有些麻烦,不够直接了当。
Superset在可视化方面做得很出色,不但是开源领域中的佼佼者,也把很多商用BI工具甩在身后。在0.20版本中支持的图表类型已经达到了36种,而且在选择图表类型时,你可以看到每一种图表的缩略图,下面这张截图大家可以感受一下
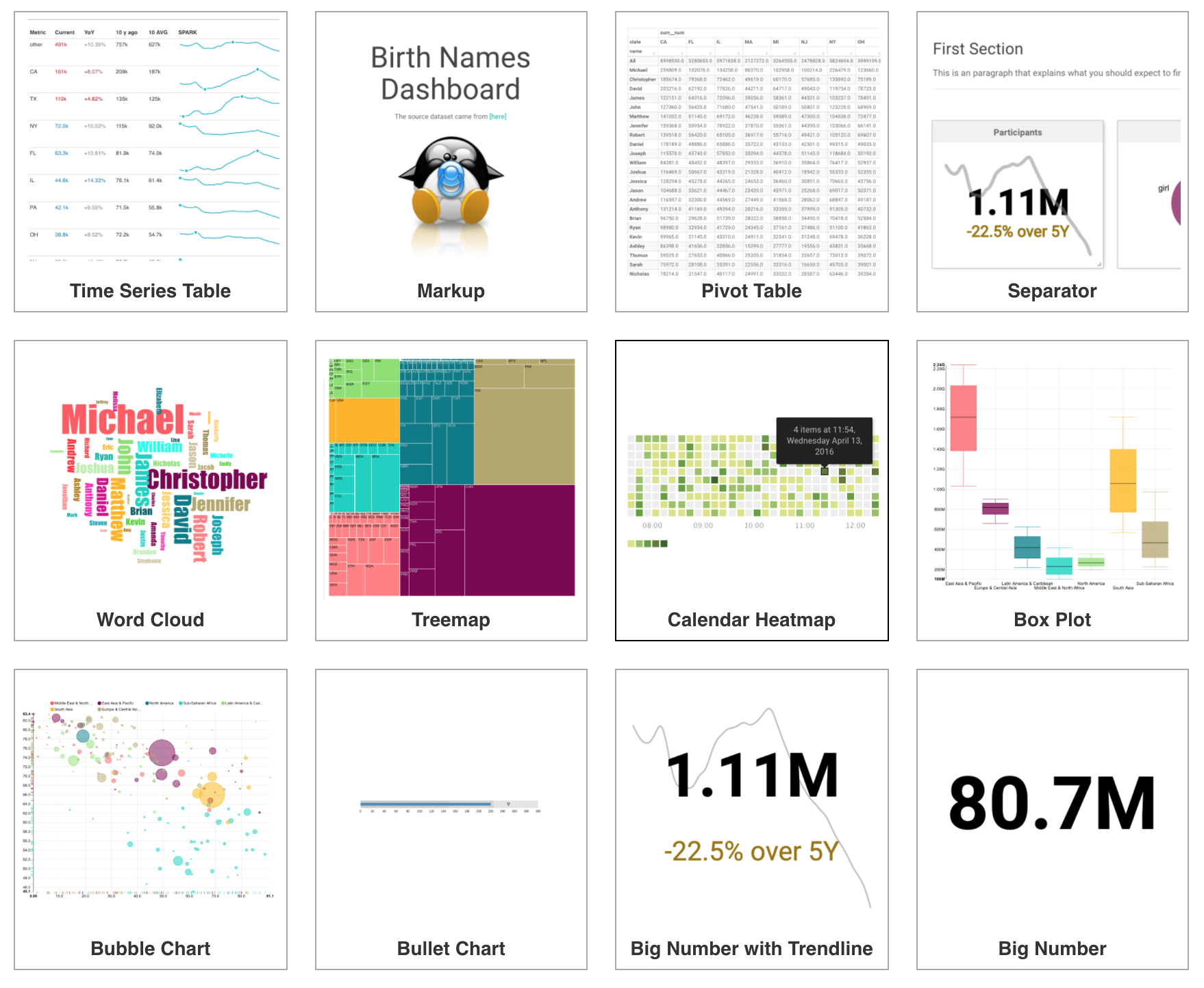
Superset的另一个亮点是可以在多个时间维度上观察,因为商业分析中的很多问题都是与时间密切相关的。Superset有4种专门针对时间序列的图表,使用这些图表时,你需要指定一个字段为时间维度,之后就可以对时间维度做丰富的操作
- 从不同时间粒度去查看你关心的指标(小时/日/周/月/季度/年)
- 对时间序列做rolling average,比如看一个指标的7日平均线
- 可以对时间序列做偏移,再做对比,比如把本周的销售业绩与上周同期放在一张图表中对比
- 不在图表上显示指标的绝对值,而是显示它随着时间变化的增长速度
以上这些都是在数据分析中非常实用的功能。
说完优点,再说说Superset的槽点,最大的槽点是当图表与报表多了以后,管理不方便。这个问题其实很好解决,只要在图表和报表管理时,加上分组或是文件夹的概念就可以了,但至今未见类似的功能。现在公司900多个图表都在一个大列表下,虽然Superset支持Search, Filter或是Favorite,但查找起来还是太麻烦。
Superset的文档也比较糟糕,虽然在安装与快速入门方面提供了很完整的文档,但在具体功能的介绍方面文档严重缺失。就算有些功能有文档,文档的结构也很混乱,所以大部分功能只能自己去尝试,好在这个工具本身并不难用,自己去摸索各个功能也不太困难。
Redash
如果说Superset是构建一个BI平台,那Redash目标就是更纯粹地做好数据查询结果的可视化。Redash支持很多种数据源,除了最常用的SQL数据库,也支持MongoDB, Elasticsearch, Google Spreadsheet甚至是一个JSON文件。Redash的官方文档里列出了它所支持的所有数据源。
它不需要像Superset那样在创建图表前先定义表和指标,而是可以非常直观地将一个SQL查询的结果可视化,这使得它上手很简易。或者说Redash仅仅实现了Superset中SQL Lab的功能,但却把这个功能做到了极致。
Redash有两个非常实用的功能,Query Snippet与Query Parameters。
Query Snippet很好地解决了查询片段的复用问题。做数据报表时经常要用到十分复杂的SQL语句,这些语句是肯定有一些片段是可以在多个Query中复用的。在Redash中我们可以将这些片段定义成Snippet,之后方便地复用。
Query Parameters可以为查询添加可定制参数,让这个图表变得更灵活。比如一个App的日活指标,我可能有时要按iOS/Android切分,有时要按地域切分,或是按新老用户切分。在Superset的Dashboard上我要做三个表图。Redash里我可以把Query的groupby做为一个参数,这样就可以在一张图上搞定。用的时候,运营人员可以图表上方的一个下拉框里选择切分的方式,非常直观好用。
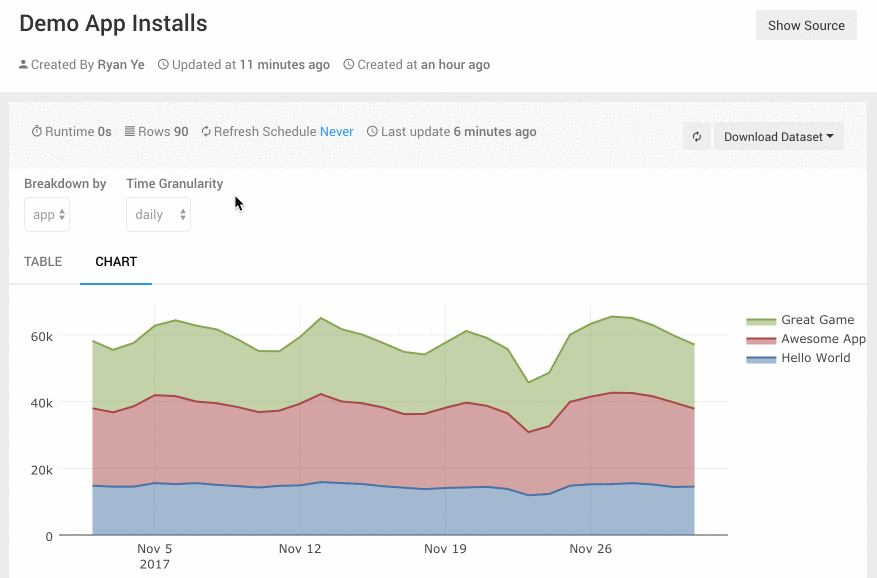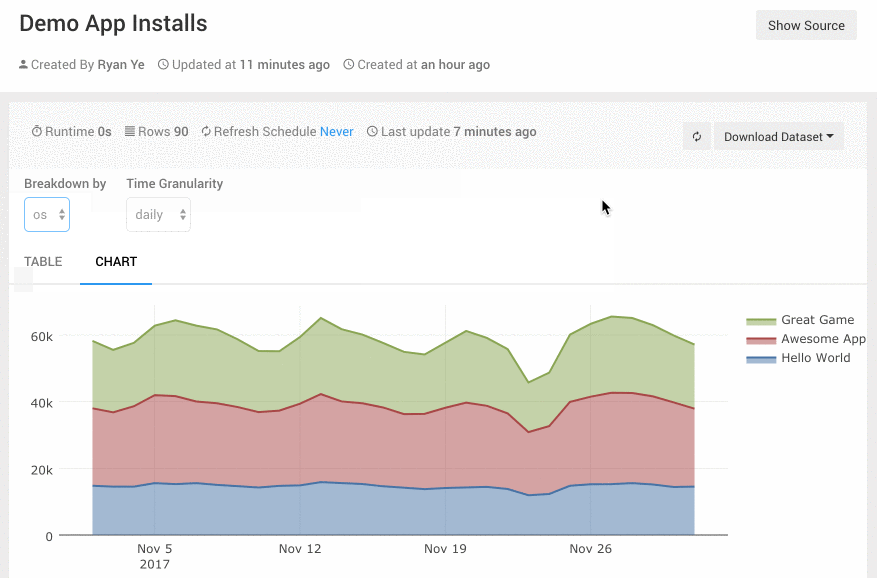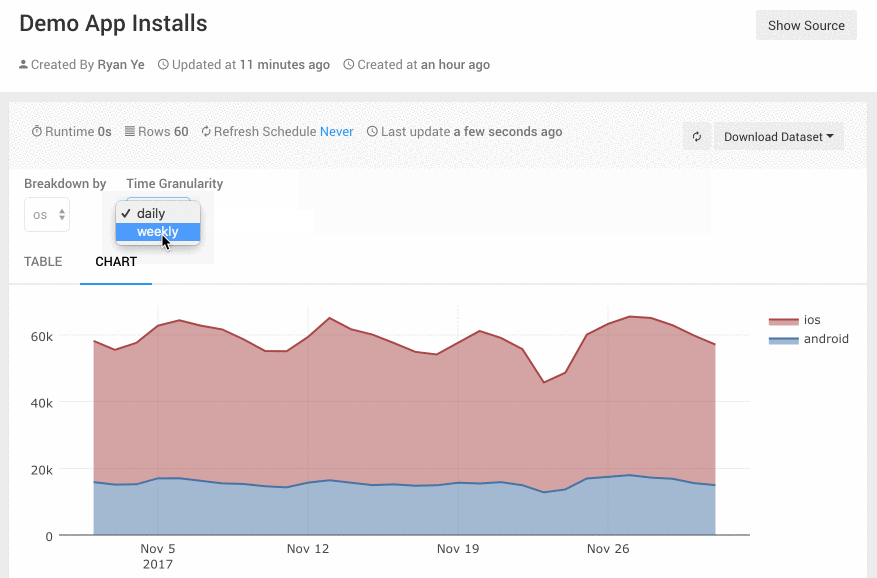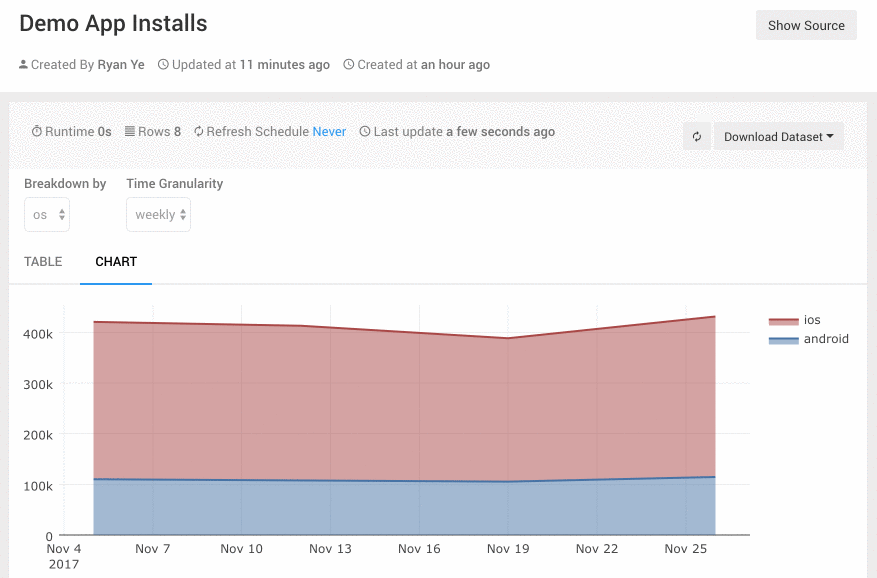
Redash的Dashboard可以通过命名来进行分组,Dashboard的名字可以有一个前缀并以冒号结尾,前缀相同的Dashboard就会自动被分为一组。例如“Growth: Daily”,“Growth: Weekly”这两个Dashboard都会被分到“Growth”组下。
相比Superset,Redash在文档方面做得更好,除了快速入门教程以外,每一个功能模块都有文档且条理清晰。
当然Redash也有自己的不足之处,它的可视化种类比Superset逊色不少(不过其实也够用了)。另外,由于它只是纯粹地把数据查询结果可视化,所以也没有Superset里那些对时间维度上的聚合与对比的操作。
Metabase
由于我并没有在生产环境下使用过Metabase,只在自己本本上试用过这个工具。所以我只能说一下对它的第一印象。
刚开始用的就觉得这个工具的界面好漂亮,明显是经过UI设计师仔细调校过的。相对的,Superset与Redash一看就是程序员充当设计师的产物。
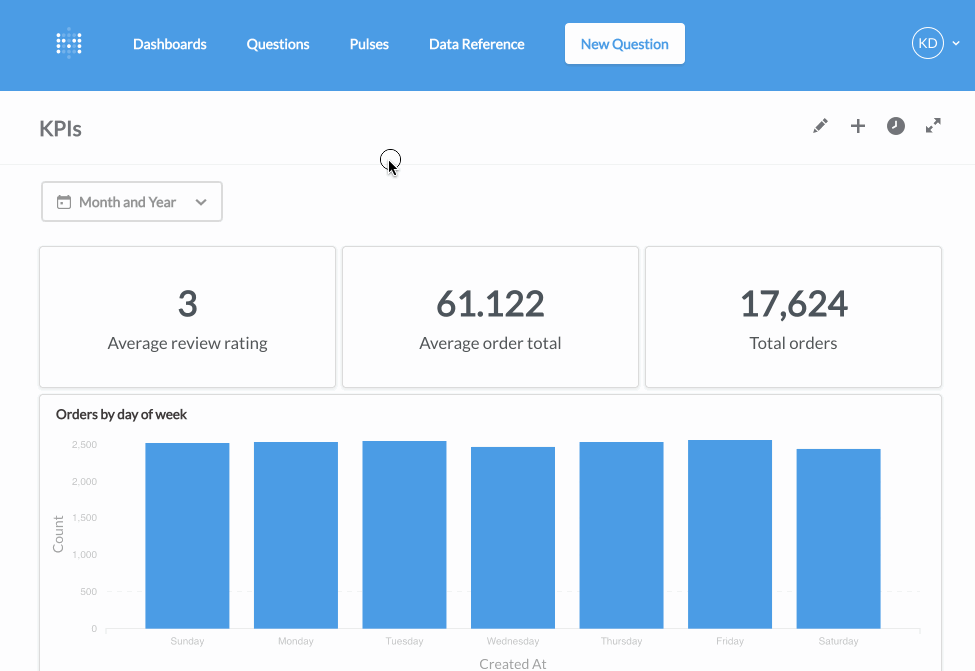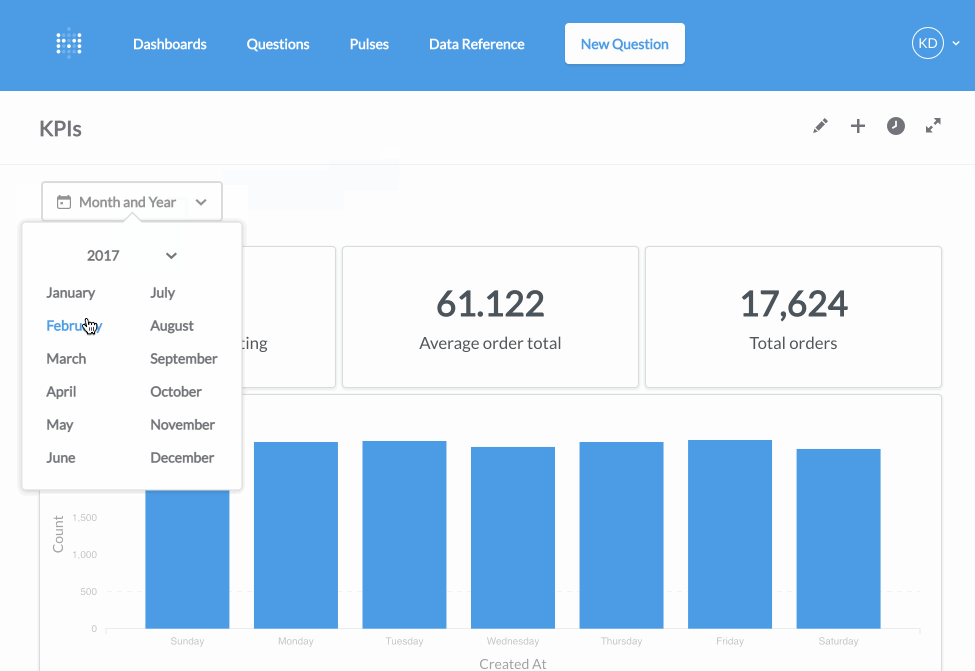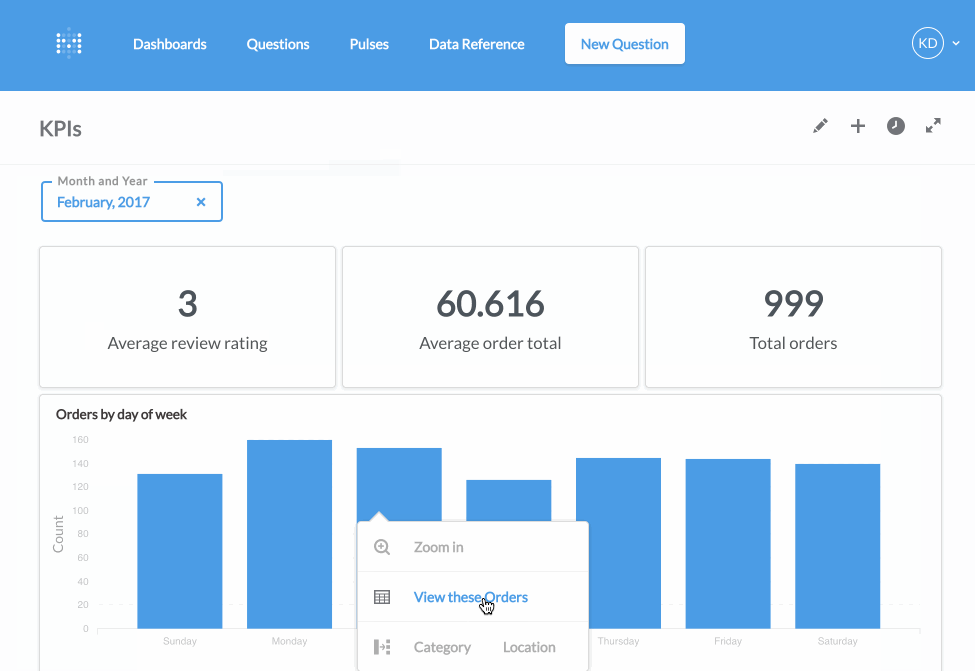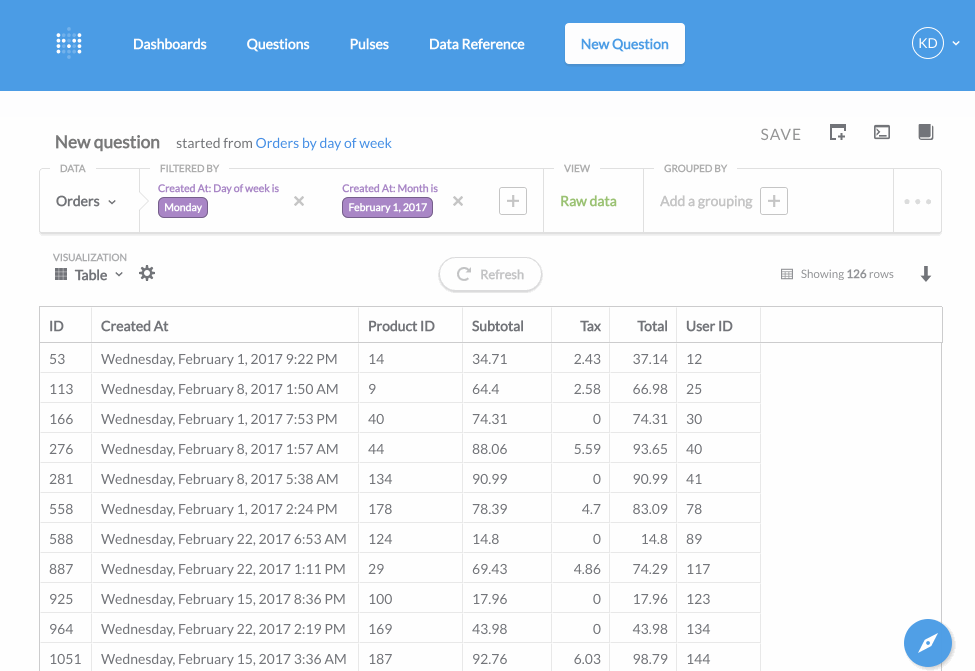
用了一会儿之后,我觉得Metabase与Superset虽然都想要打造一个完整的BI平台,但在理念上是不同的。Metabase非常注重非技术人员(如产品经理、市场运营人员)在使用这个工具时的体验,让他们能自由地探索数据,回答自己的问题。而在Superset或是Redash里,非技术人员基本上只能看预先建好的Dashboard,不懂SQL或是数据库结构的他们,很难自己去摸索。我非常喜欢Metabase的理念,它更接近一款成熟的商业化产品。当然要把这个理念变为现实是很有挑战的,目前我不知道在面临复杂的真实业务环境中,Metabase是否有想像中那样美好。
另外值得一提的是,Metabase的文档也是三个项目中写得最好最完整的,内容非常丰富。
将来若是有机会,我很愿意更深入地去体验这个产品。
小结
本文简单地介绍了三个开源的数据可视化工具Superset, Redash和Metabase,三者各有所长,我觉得并不存在绝对的最强者。对于刚刚开始搭建BI平台的公司,我相信它们都可以满足大部分报表与业务分析的需求。
虽然Superset是我们公司现在主要使用的可视化工具,但我问过自己“如果现在让我重新选择,我会使用哪个开源项目?”我的答案是Redash,而原因主要不是功能层面,而是技术层面。这里正好可以引出我们下篇要聊的内容,从技术框架与源代码层面来比较一下这三个项目,以及我选择开源项目的一些通用原则,敬请期待!