This is a Python wrapper for TA-LIB based on Cython instead of SWIG. From the homepage:
TA-Lib is widely used by trading software developers requiring to perform technical analysis of financial market data.
- Includes 150+ indicators such as ADX, MACD, RSI, Stochastic, Bollinger Bands, etc.
- Candlestick pattern recognition
- Open-source API for C/C++, Java, Perl, Python and 100% Managed .NET
The original Python bindings use SWIG which unfortunately are difficult to install and aren’t as efficient as they could be. Therefore this project uses Cython and Numpy to efficiently and cleanly bind to TA-Lib — producing results 2-4 times faster than the SWIG interface.
Install TA-Lib or Read the Docs
Examples
Similar to TA-Lib, the function interface provides a lightweight wrapper of the exposed TA-Lib indicators.
Each function returns an output array and have default values for their parameters, unless specified as keyword arguments. Typically, these functions will have an initial “lookback” period (a required number of observations before an output is generated) set to NaN.
All of the following examples use the function API:
import numpy
import talib
close = numpy.random.random(100)
Calculate a simple moving average of the close prices:
output = talib.SMA(close)
Calculating bollinger bands, with triple exponential moving average:
from talib import MA_Type
upper, middle, lower = talib.BBANDS(close, matype=MA_Type.T3)
Calculating momentum of the close prices, with a time period of 5:
output = talib.MOM(close, timeperiod=5)
Abstract API Quick Start
If you’re already familiar with using the function API, you should feel right at home using the abstract API. Every function takes the same input, passed as a dictionary of Numpy arrays:
import numpy as np
# note that all ndarrays must be the same length!
inputs = {
'open': np.random.random(100),
'high': np.random.random(100),
'low': np.random.random(100),
'close': np.random.random(100),
'volume': np.random.random(100)
}
Functions can either be imported directly or instantiated by name:
from talib import abstract
sma = abstract.SMA
sma = abstract.Function('sma')
From there, calling functions is basically the same as the function API:
from talib.abstract import *
output = SMA(input_arrays, timeperiod=25) # calculate on close prices by default
output = SMA(input_arrays, timeperiod=25, price='open') # calculate on opens
upper, middle, lower = BBANDS(input_arrays, 20, 2, 2)
slowk, slowd = STOCH(input_arrays, 5, 3, 0, 3, 0) # uses high, low, close by default
slowk, slowd = STOCH(input_arrays, 5, 3, 0, 3, 0, prices=['high', 'low', 'open'])
Learn about more advanced usage of TA-Lib here.
Supported Indicators
We can show all the TA functions supported by TA-Lib, either as a list or as a dict sorted by group (e.g. “Overlap Studies”, “Momentum Indicators”, etc):
import talib
print talib.get_functions()
print talib.get_function_groups()
Function Groups
- Overlap Studies
- Momentum Indicators
- Volume Indicators
- Volatility Indicators
- Price Transform
- Cycle Indicators
- Pattern Recognition
- Statistic Functions
- Math Transform
- Math Operators
Overlap Studies
BBANDS Bollinger Bands
DEMA Double Exponential Moving Average
EMA Exponential Moving Average
HT_TRENDLINE Hilbert Transform - Instantaneous Trendline
KAMA Kaufman Adaptive Moving Average
MA Moving average
MAMA MESA Adaptive Moving Average
MAVP Moving average with variable period
MIDPOINT MidPoint over period
MIDPRICE Midpoint Price over period
SAR Parabolic SAR
SAREXT Parabolic SAR - Extended
SMA Simple Moving Average
T3 Triple Exponential Moving Average (T3)
TEMA Triple Exponential Moving Average
TRIMA Triangular Moving Average
WMA Weighted Moving AverageMomentum Indicators
ADX Average Directional Movement Index
ADXR Average Directional Movement Index Rating
APO Absolute Price Oscillator
AROON Aroon
AROONOSC Aroon Oscillator
BOP Balance Of Power
CCI Commodity Channel Index
CMO Chande Momentum Oscillator
DX Directional Movement Index
MACD Moving Average Convergence/Divergence
MACDEXT MACD with controllable MA type
MACDFIX Moving Average Convergence/Divergence Fix 12/26
MFI Money Flow Index
MINUS_DI Minus Directional Indicator
MINUS_DM Minus Directional Movement
MOM Momentum
PLUS_DI Plus Directional Indicator
PLUS_DM Plus Directional Movement
PPO Percentage Price Oscillator
ROC Rate of change : ((price/prevPrice)-1)*100
ROCP Rate of change Percentage: (price-prevPrice)/prevPrice
ROCR Rate of change ratio: (price/prevPrice)
ROCR100 Rate of change ratio 100 scale: (price/prevPrice)*100
RSI Relative Strength Index
STOCH Stochastic
STOCHF Stochastic Fast
STOCHRSI Stochastic Relative Strength Index
TRIX 1-day Rate-Of-Change (ROC) of a Triple Smooth EMA
ULTOSC Ultimate Oscillator
WILLR Williams' %RVolume Indicators
AD Chaikin A/D Line
ADOSC Chaikin A/D Oscillator
OBV On Balance VolumeVolatility Indicators
ATR Average True Range
NATR Normalized Average True Range
TRANGE True RangePrice Transform
AVGPRICE Average Price
MEDPRICE Median Price
TYPPRICE Typical Price
WCLPRICE Weighted Close PriceCycle Indicators
HT_DCPERIOD Hilbert Transform - Dominant Cycle Period
HT_DCPHASE Hilbert Transform - Dominant Cycle Phase
HT_PHASOR Hilbert Transform - Phasor Components
HT_SINE Hilbert Transform - SineWave
HT_TRENDMODE Hilbert Transform - Trend vs Cycle ModePattern Recognition
CDL2CROWS Two Crows
CDL3BLACKCROWS Three Black Crows
CDL3INSIDE Three Inside Up/Down
CDL3LINESTRIKE Three-Line Strike
CDL3OUTSIDE Three Outside Up/Down
CDL3STARSINSOUTH Three Stars In The South
CDL3WHITESOLDIERS Three Advancing White Soldiers
CDLABANDONEDBABY Abandoned Baby
CDLADVANCEBLOCK Advance Block
CDLBELTHOLD Belt-hold
CDLBREAKAWAY Breakaway
CDLCLOSINGMARUBOZU Closing Marubozu
CDLCONCEALBABYSWALL Concealing Baby Swallow
CDLCOUNTERATTACK Counterattack
CDLDARKCLOUDCOVER Dark Cloud Cover
CDLDOJI Doji
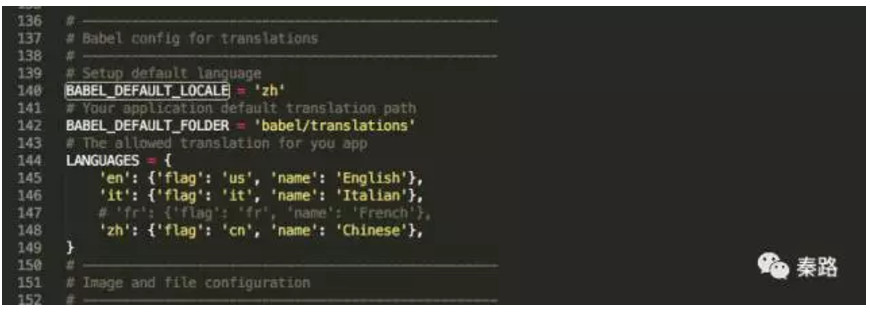
CDLDOJISTAR Doji Star
CDLDRAGONFLYDOJI Dragonfly Doji
CDLENGULFING Engulfing Pattern
CDLEVENINGDOJISTAR Evening Doji Star
CDLEVENINGSTAR Evening Star
CDLGAPSIDESIDEWHITE Up/Down-gap side-by-side white lines
CDLGRAVESTONEDOJI Gravestone Doji
CDLHAMMER Hammer
CDLHANGINGMAN Hanging Man
CDLHARAMI Harami Pattern
CDLHARAMICROSS Harami Cross Pattern
CDLHIGHWAVE High-Wave Candle
CDLHIKKAKE Hikkake Pattern
CDLHIKKAKEMOD Modified Hikkake Pattern
CDLHOMINGPIGEON Homing Pigeon
CDLIDENTICAL3CROWS Identical Three Crows
CDLINNECK In-Neck Pattern
CDLINVERTEDHAMMER Inverted Hammer
CDLKICKING Kicking
CDLKICKINGBYLENGTH Kicking - bull/bear determined by the longer marubozu
CDLLADDERBOTTOM Ladder Bottom
CDLLONGLEGGEDDOJI Long Legged Doji
CDLLONGLINE Long Line Candle
CDLMARUBOZU Marubozu
CDLMATCHINGLOW Matching Low
CDLMATHOLD Mat Hold
CDLMORNINGDOJISTAR Morning Doji Star
CDLMORNINGSTAR Morning Star
CDLONNECK On-Neck Pattern
CDLPIERCING Piercing Pattern
CDLRICKSHAWMAN Rickshaw Man
CDLRISEFALL3METHODS Rising/Falling Three Methods
CDLSEPARATINGLINES Separating Lines
CDLSHOOTINGSTAR Shooting Star
CDLSHORTLINE Short Line Candle
CDLSPINNINGTOP Spinning Top
CDLSTALLEDPATTERN Stalled Pattern
CDLSTICKSANDWICH Stick Sandwich
CDLTAKURI Takuri (Dragonfly Doji with very long lower shadow)
CDLTASUKIGAP Tasuki Gap
CDLTHRUSTING Thrusting Pattern
CDLTRISTAR Tristar Pattern
CDLUNIQUE3RIVER Unique 3 River
CDLUPSIDEGAP2CROWS Upside Gap Two Crows
CDLXSIDEGAP3METHODS Upside/Downside Gap Three MethodsStatistic Functions
BETA Beta
CORREL Pearson's Correlation Coefficient (r)
LINEARREG Linear Regression
LINEARREG_ANGLE Linear Regression Angle
LINEARREG_INTERCEPT Linear Regression Intercept
LINEARREG_SLOPE Linear Regression Slope
STDDEV Standard Deviation
TSF Time Series Forecast
VAR Variance